Phased Approach
Path to Quality Parity
Phase 1
Months 1-2
77%
70-85% of Veo quality
Side-by-side benchmark against your actual Veo output. Product shots and B-roll already very close. Lip sync via two-stage pipeline (video gen + dedicated sync model).
Phase 2
Months 3-5
87%
80-95% of Veo quality
Optimized workflows tuned to your ad formats. State creative batch automation fully operational. Lip sync pipeline refined for podcast-style talking heads.
Phase 3
Months 6-12
97%
90-100%+ matches or exceeds Veo
Custom models trained on YOUR ad style beat generic cloud output. Next-gen lip sync models (SkyReels V4, daVinci) expected to close the remaining gap.
Artificial Analysis / Text-to-Video with Audio / March 2026
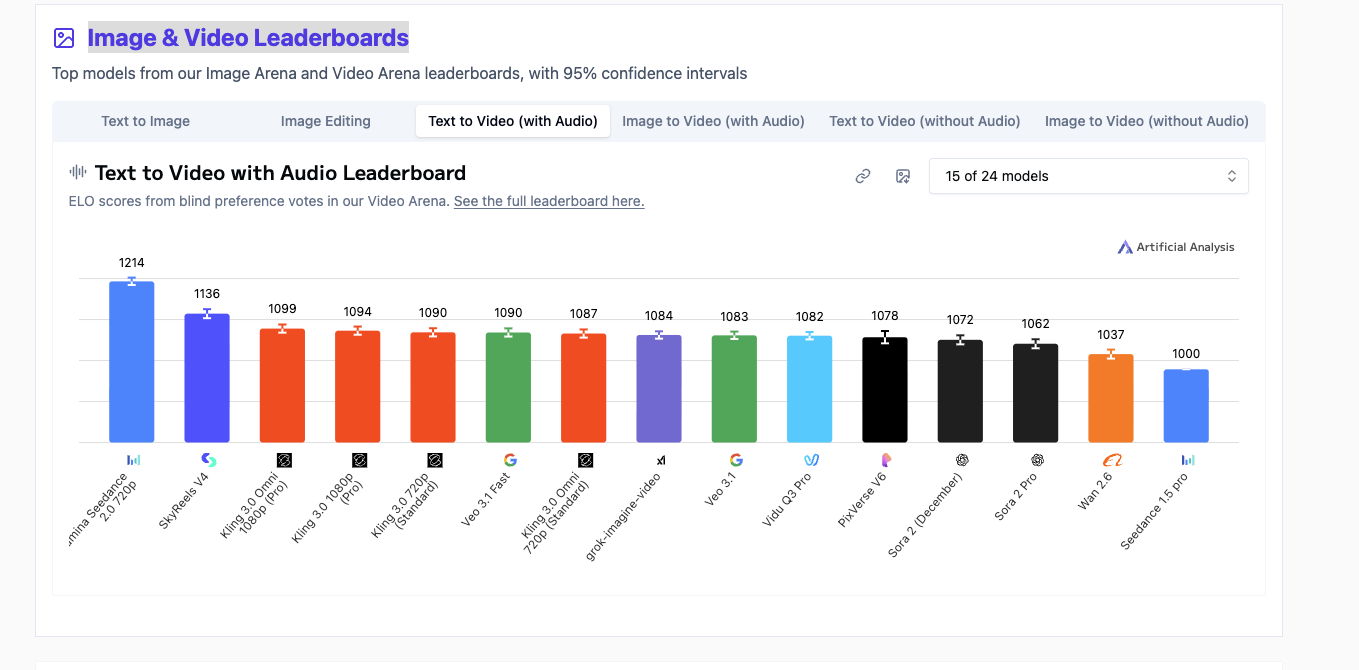
Elo scores from blind preference votes. SkyReels V4 (open) beats multiple Veo variants. Live leaderboard →